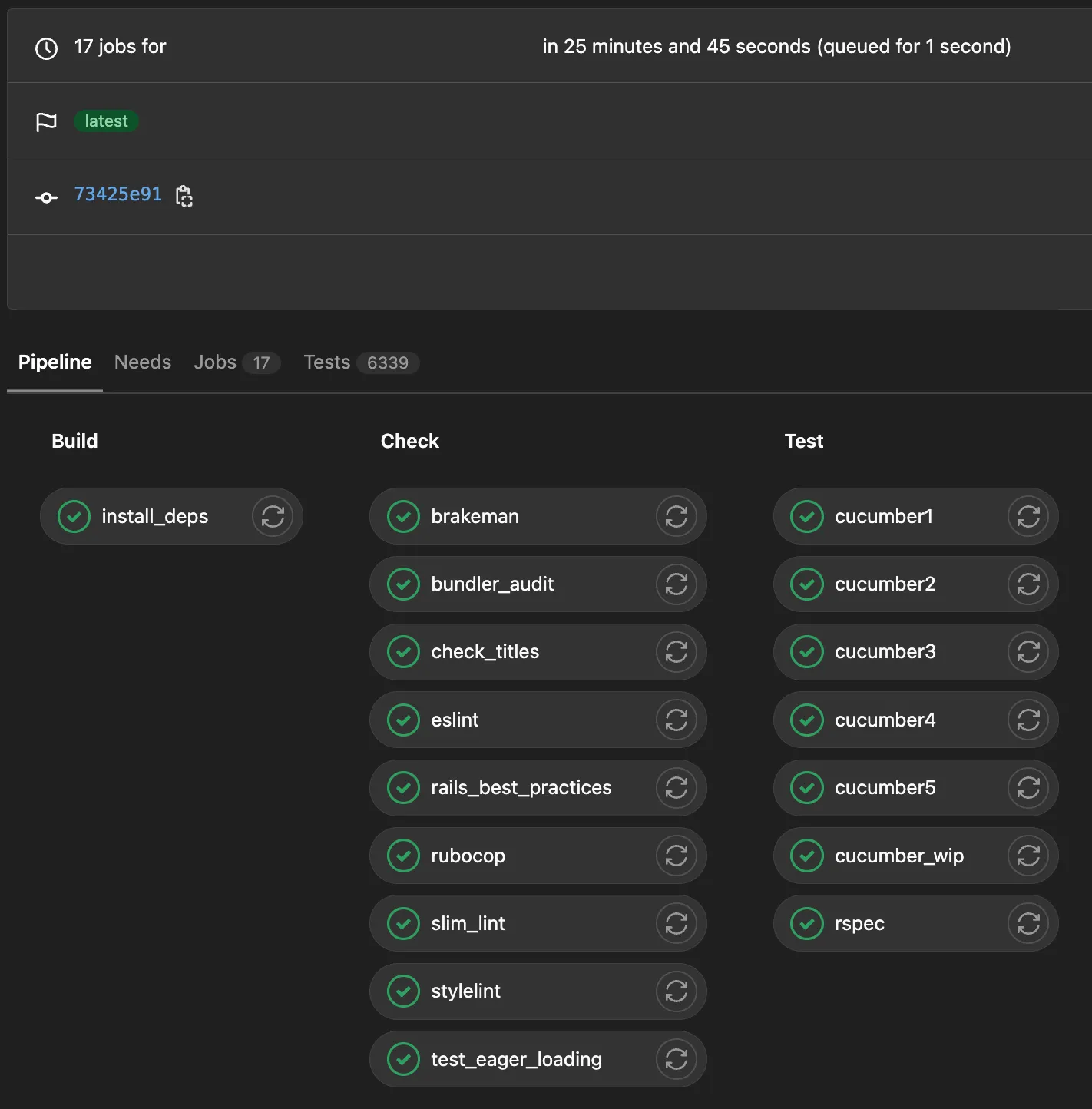
When you’re working on a Rails application with ~100 feature files containing a total of 685 scenarios, it’s really important to spend time pruning and optimising your CI build.
Our build time had been slowly creeping up and whilst we had spent time pruning our features and only running scenarios in a headless browser where necessary, we were still in a predicament. Our CI pipeline was taking between 50 mins and 1 hour to complete, nearly all of that time was running our Cucumber tests.
While this problem may point to other bigger questions such as “is this application doing too much?”, “should we split this into separate apps?” and “how did it get this slow?”, such questions rarely have a quick and cheap answer.
Therefore I paired up with my colleague Glenn Baker and we set to work in pursuit of a solution.
Parallelizing
One quick win which often yields results is running your tests in parallel. There’s a popular gem called parallel_tests which allows you to run Test::Unit, RSpec, Cucumber or Spinach tests in parallel on multiple CPU cores concurrently.
We had used this gem in the past but removed it after facing many issues with flapping tests and timeouts. I suspect this was no fault of the gem, rather our use of it or poor tests causing side effects.
Either way, this post will describe an alternative approach using concurrent GitLab jobs.
Alternative approach - GitLab jobs
To define a GitLab job it’s a simple case of adding a block to the .gitlab-ci.yml file.
cucumber:
extends: .test
script:
- bundle exec rake cucumber
Each block will become a job and there’s a concurrent config option in the GitLab runners config.toml file which defines the number of concurrent jobs
which can run at once.
We changed our config to have multiple cucumber jobs, setting an environment variable to give each job an ID.
cucumber1:
extends: .test
script:
- bundle exec rake cucumber CUCUMBER_GROUP=1
...
cucumber2:
extends: .test
script:
- bundle exec rake cucumber CUCUMBER_GROUP=2
...
Slicing the Cucumber
Using this environment variable, we were able to decide which portion of the features to run on each job. The next thing was to implement the slicing up of our feature tests.
Approach 1 - splitting by files
As a first pass, we simply split the .feature files between each job. To actually do this, it was a case of modifying our
rake task, passing the list of feature files we want to run as a string to t.cucumber_opts=.
We find all the .feature files in our project, work out how many files to run on each job and then call Array#in_groups_of to split the files
into separate arrays.
Then we can use the CUCUMBER_GROUP variable to pick the appropriate group.
Cucumber::Rake::Task.new do |t|
feature_files = Dir.glob(Rails.root.join("features/**/*.feature"))
group_size = feature_files.count / 4
grouped_features = feature_files.in_groups_of(group_size)
t.cucumber_opts = grouped_features[ENV["CUCUMBER_GROUP"].to_i - 1].compact.join(" ")
# ...
end
Approach 1 comes with a problem. Some feature files will have more scenarios than others. Using this approach resulted in one of the jobs running twice as many scenarios as another meaning the load wasn’t evenly spread between the jobs.
Approach 2 - evenly spreading the load
tl;dr view full solution.
To improve the distribution between jobs we decided to split the feature files based on the number of scenarios in each file. The regular expression below will also include the number of scenario outlines.
def scenario_count(filepath)
File.read(filepath).scan(/Scenario:|(?<!Examples:\s)^\s*\|/).count
end
Once we had the count for each file, we can sort the features by the number of scenarios.
feature_files.map { |filepath| [filepath, scenario_count(filepath)] }
.sort_by { |_file, count| count }
.map { |file, _count| file }
Now all that’s left to do is distribute the features between a number of arrays equal to the number of GitLab jobs we have.
To do this we wrote a small recursive method to place the feature files sequentially into each array. This works through the ordered features and places each one into subsequent groups.
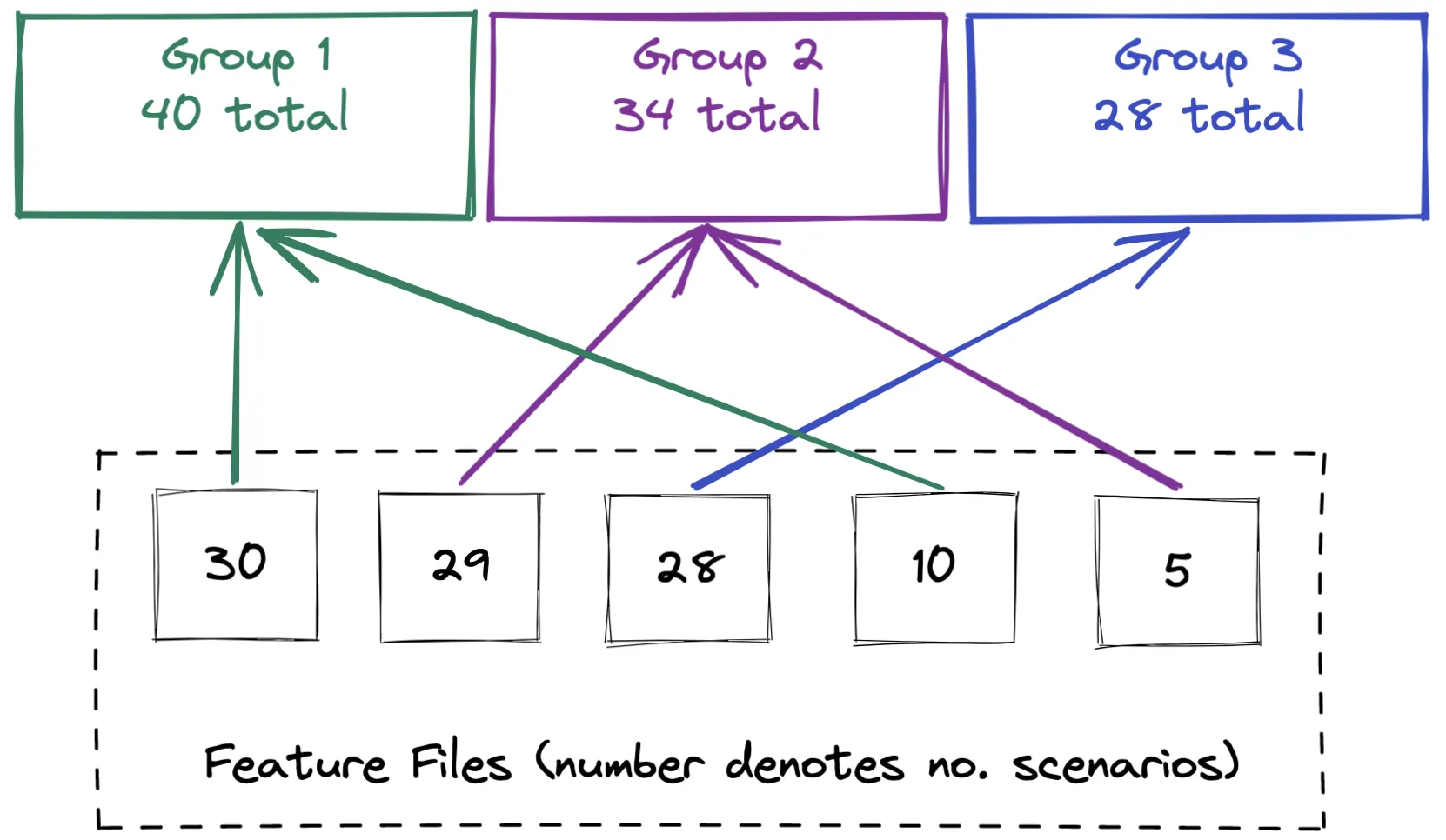
def populate_slices(slices, slice_index, features)
return slices if features.count.zero?
slices[slice_index] << features.pop
populate_slices(slices, (slice_index + 1) % @num_slices, features)
end
The recursive approach achieved good results, good enough to push to main and start feeling the benefit of the time saving. However, Glenn and I felt we could still shave a few more minutes off.
Approach 3 - limitting how big a group can get
tl;dr view full solution.
The recursive approach above can still result in the groups being unbalanced when there is a large disparity between scenario counts of the feature files.
To resolve this we needed to set a limit of how many scenarios each group should hold. We changed our slices array to be an array of hashes, so we could store the filepath strings along with the number of scenarios each group has at any one time.
def initialize_slices(num_slices)
Array.new(num_slices) { { scenario_count: 0, feature_filepaths: [] } }
end
Our feature_files also becomes an array of hashes so we can store each feature’s scenario count and filepath e.g. { scenario_count: 14, feature_filepath: "features/login.feature" }
Then we can loop over our feature files and find the next available group which has capacity to hold the feature file before adding the feature to the group.
slices = initialize_slices(num_slices)
features_files.each do |feature|
slice = pick_a_slice(slices, feature[:scenario_count], average_scenario_count)
add_feature_to_a_slice(feature, slice)
end
Let’s unpick these methods a bit. pick_a_slice uses Enumerable#find to find the first slice where the slices current scenario count + the feature we’re trying to add to it is less than the limit.
def pick_a_slice(slices, feature_size, target_size)
slices.find { |slice| (slice[:scenario_count] + feature_size) < target_size }
end
Once we’ve found the slice with available space, we update the slice’s count and add the feature filepath to it.
def add_feature_to_a_slice(feature, slice)
slice[:scenario_count] += feature[:scenario_count]
slice[:feature_filepaths] << feature[:feature_filepath]
end
Using the slicer
Back in our Rake task it was then just a case of updating our Rake task to use our CucumberSlicer class.
Cucumber::Rake::Task.new do |t|
if ENV["CUCUMBER_GROUP"].present?
sliced_features = CucumberSlicer.slice(num_slices: 5)
t.cucumber_opts = sliced_features[ENV["CUCUMBER_GROUP"].to_i - 1].compact.join(" ")
end
# ...
end
Conclusion
All in all it was well worth the effort spent, over halving our pipeline run time. There’s still work to do but having our pipelines like the one below finish within around 25 minutes has been a breath of fresh air for the whole development team.